We live in an era where no one can truly be independent of others, and those who wish to be in the same space can come together almost instantly. Isn’t this the essence of cloud technologies as well? To integrate seamlessly into an inseparable whole, as swiftly as possible. Data behaves in much the same way — regardless of where it resides, it needs to communicate, to be understood, and to be organized. This creates a need for an environment where data from different sources can work together.
Today, companies are no longer satisfied with sticking to a single platform. Instead, they are leveraging solutions from various technology giants to achieve greater outcomes. For instance, they might train AI models within Amazon’s secure ecosystem and then visualize the results using Microsoft’s Power BI, a powerful business intelligence tool. At this point, the importance of creating a common ground where platforms can “communicate” to each other becomes evident.
Microsoft Fabric steps in as a comprehensive data management system to address this need. It connects to data stored in Amazon S3 buckets, organizes and structures it, and finally makes it ready for visualization. This is the true power of cloud technologies: bringing everything together to form a meaningful whole.

Let’s dive into the details of this process!
1. Setting Up S3 Connection with Data Factory
> The first step is to create a pipeline in Data Factory.
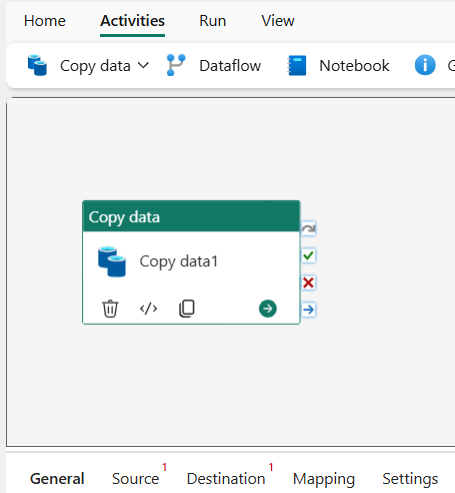
> Within the pipeline, we create a “Copy data” activity to define the source and destination environments.
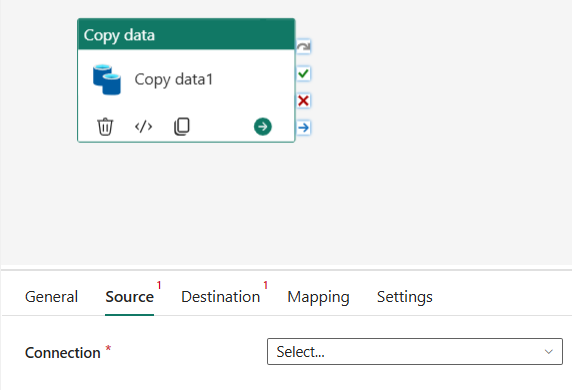
> The first interaction between Amazon and Microsoft environments happens in the source step.
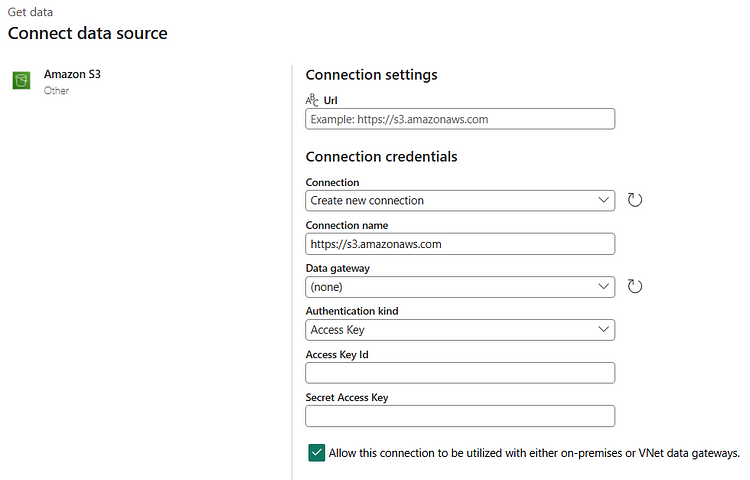
> When you select “Amazon S3” as the connection option, you will be prompted to enter your connection details. By providing the Access Key ID and Secret Access Key information found in the AWS Management Console, the connection is established.
> Now, you have access to your Amazon S3 bucket via Microsoft Fabric. After entering the S3 bucket details, you can retrieve any table you need. But where to?

> OneLake is a unified data repository within Microsoft Fabric that allows you to host data and models from different sources. You can also create Lakehouses inside it and store your data there. The storage areas you create here will serve as your destination environment.
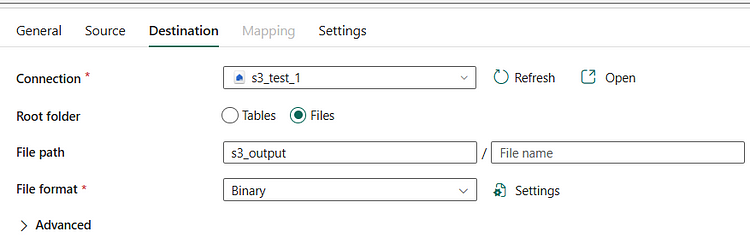
> That’s it! Once this flow is executed, all you need to do to regularly retrieve data from Amazon S3 is the correct programming.

2. Using OneLake Shortcuts
Another method is accessing data via an Amazon S3 connection created on OneLake without physically transferring the data. This method is used when there is a need for direct live access to data without making any modifications.
> First, we create a LakeHouse and add a new shortcut to Amazon S3.

> Connection details, as in the first method, can be obtained through the AWS Console.
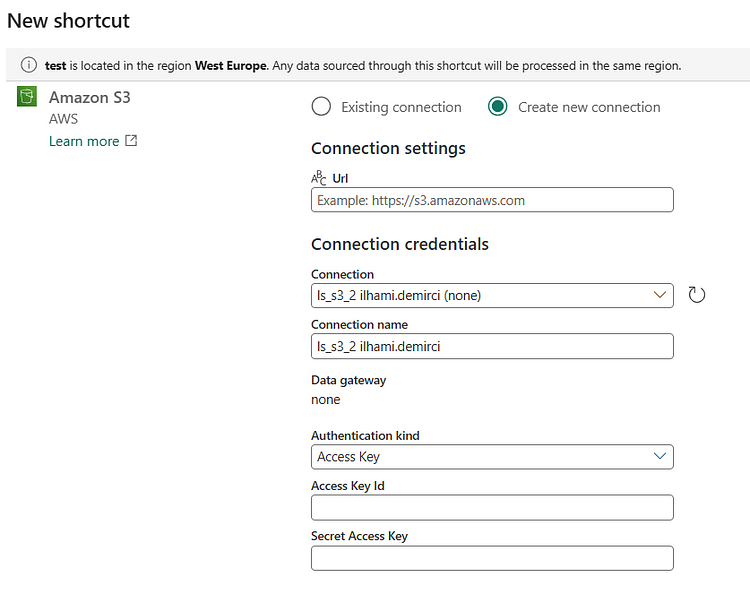
> Once the connection is established, you can access any table. However, be sure that the accessed data and the source data are in the same region.
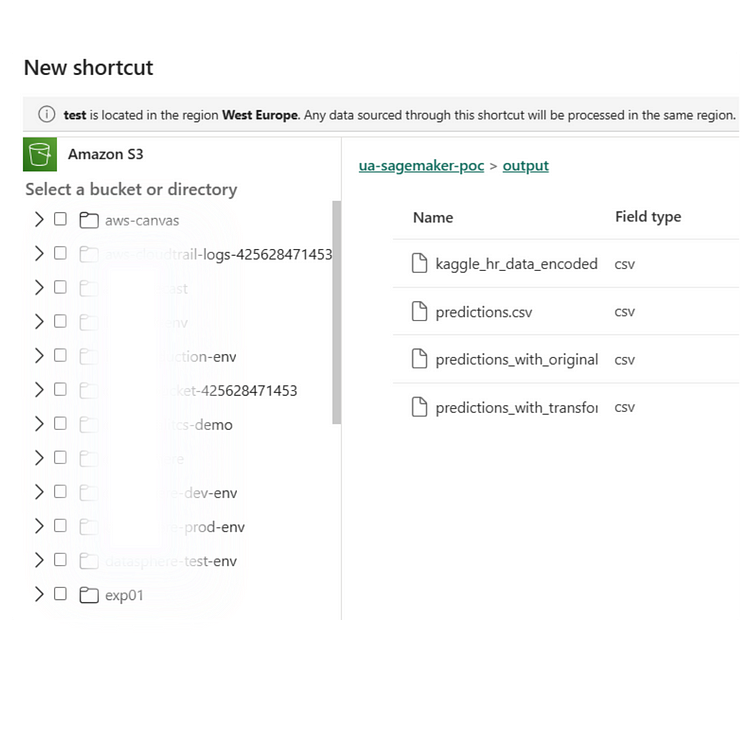
With both methods, we brought together different technological infrastructures and provided the environment that data requires. The world of data is made up of interconnected pieces, and when each component is properly integrated, we can achieve the most efficient results.
Cloud technologies are just the beginning; true success lies in how you integrate these technologies into your business processes and how you transform your data.